Intro
The RTX 2000 ADA is a dual slot half height workstation GPU with 16GB VRAM. With just 168mm in length, it’s amongst the few GPUs that can derive power from the PCIe slot, thereby removing the need for external power connectors.
I came across it while searching for a graphics card that can fit in Minisforum MS-01. If you aren’t familiar with the MS-01, here’s the specs:
-
13900H w/ 14cores (20 threads)
-
2x10G POE+ and 2x 2.5GbE (total networking throughput of 25Gbps)
-
upto 128GB DDR5 RAM (dual sodimms)
-
upto 24TB SSD (3x NVME slot)
-
Full PCIe 4.0 x16 lane for GPU (limited to x8 speed)
All of this in a mere 1.8L volume (Xbox controller for size reference). An ideal SFF workstation.




Why workstation GPU when there are more capable consumer cards at lower prices?
It’s a fact that you can get RTX 4060ti 16GB at INR 10k less. And being AD106 die, it’ll outperform the 2000 Ada which is AD107 die. But there were few constraints :
-
The RTX 4060ti consumes about 2.4x more electricity. At Rs 8/kWh, you’ll break even in 1.5yrs, and further save ~INR 25k (net) in 5yrs.
-
Higher TDP brings more heat, and you can’t fit it into a sub 2L case.
-
Needs 16 pin power connector. The 2000 Ada is plug and play (draws power from PCIe slot)
-
No ECC memory
-
Lacks enterprise support.
Now there are few more half height single slot cards which can fit here. AMD RX 6400, Intel ARC A310, RTX A2000, RTX 2000E ADA and RTX 4000 SFF ADA.
I was initially looking for [RTX 4000 SFF Ada](’
RTX A4000 SFF ADA - Looking to Buy - TechEnclave’
). It is the most powerful GPU you can fit in MS-01. But thanks to @@ibose , I stumbled upon the RTX 2000 ADA. I initially struggled to find any reviews of this device. This[ japanese reviewer](’
「NVIDIA RTX 2000 Ada」をフォトレビュー。ベンチマークも少し 【PR】 | 自作とゲームと趣味の日々’
) was the only place you could find some realistic and verifiable benchmarks. There was also Ampere generation RTX A2000 12GB at a cheaper price, but I decided to go with the ADA generation. You can [read why here](’
「NVIDIA RTX 2000 Ada」をフォトレビュー。ベンチマークも少し 【PR】 | 自作とゲームと趣味の日々’
).
It’s important to note that Nvidia has not launched any SFF workstation cards for their Blackwell generation (Pro Series).
Overall Cost
Total : $785 + INR 58k = About 120k INR
Benchmarks
In synthetic benchmarks, the 2000 ADA scores (graphics only):
Time Spy : 8086 running native, 7432 running inside proxmox VM with GPU passthrough
Time Spy Extreme : 3646 running native
Speedway : 2000 running native
Fire Strike : 22206 running native
Fire Strike Extreme : 9929 running native
Port Royale : 4600 running native
1. GAMING BENCHMARKS
System Configuration: MS-01 running Proxmox (Windows Server 2025, 24H2, with 12 vCPU, 16GB RAM, 512GB SSD).
DLSS if ON will be set to Quality in CNN Models (DLSS 3) and Performance in Transformer models (DLSS 4).




On average, the RTX 2000 Ada 16GB is 32% faster than RTX A2000 12GB ([source](’
https://www.notebookcheck.net/Nvidia-RTX-A2000-Benchmarks-and-Specs.885631.0.html’
)), while costing 28% more
On average, the RTX 2000 Ada 16GB is 23% slower than RTX 4000 SFF ADA 20GB ([src1](’
「NVIDIA RTX 4000 SFF Ada」をレビュー。RTX A2000よりも60%以上高速に! | 自作とゲームと趣味の日々’
), [src2](’
https://youtu.be/KGIEO1xUAcA?si=90G0z_00ngGWhZdy’
)), while costing 49% less
[HEADING=1]2. LLM BENCHMARKS [/HEADING]
System Configuration: MS-01 running Llama.cpp in Proxmox LXC (20 vCPU, 16GB VRAM, 24GB RAM, 256GB SSD).
Memory Configuration : Flash Attention ON, K_V Quantisation Enabled, Context window : 4096 tokens
FP8 support in Ada generation provides a higher dynamic range compared to INT8, which helps in quantizing model components like weights and activations without significant loss of information. In contrast, Ampere GPUs (eg RTX A2000) only support weight-only FP8 (W8A16) using Marlin kernels.

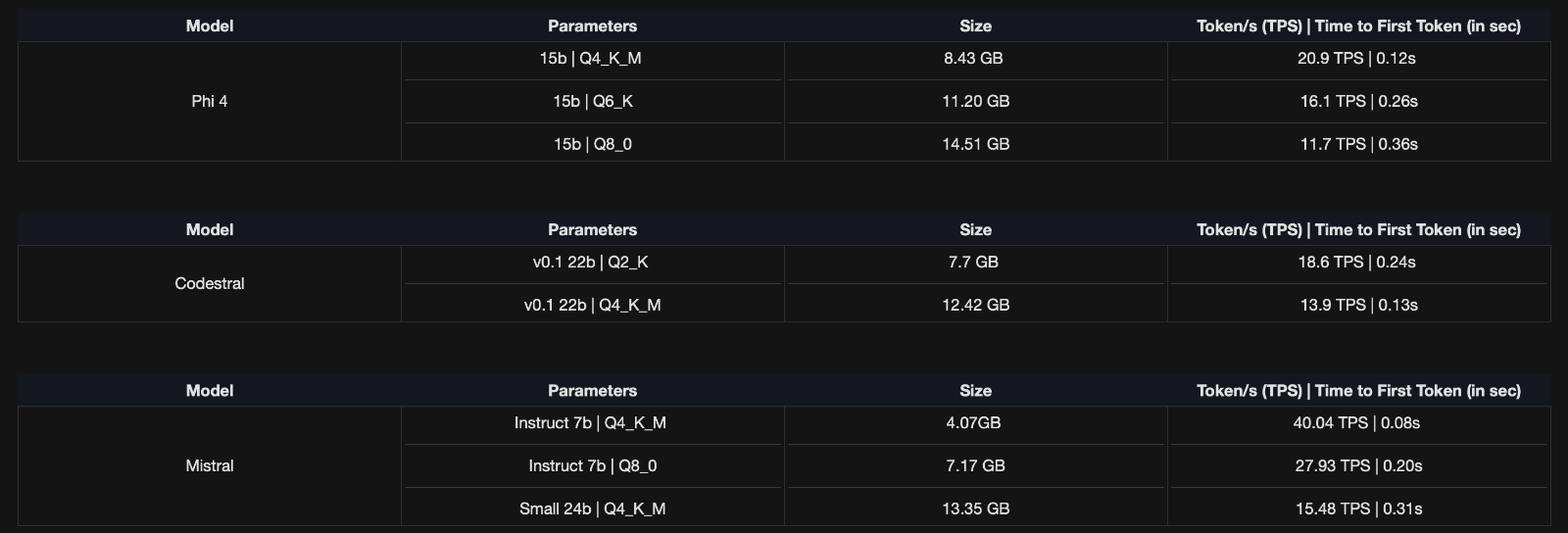
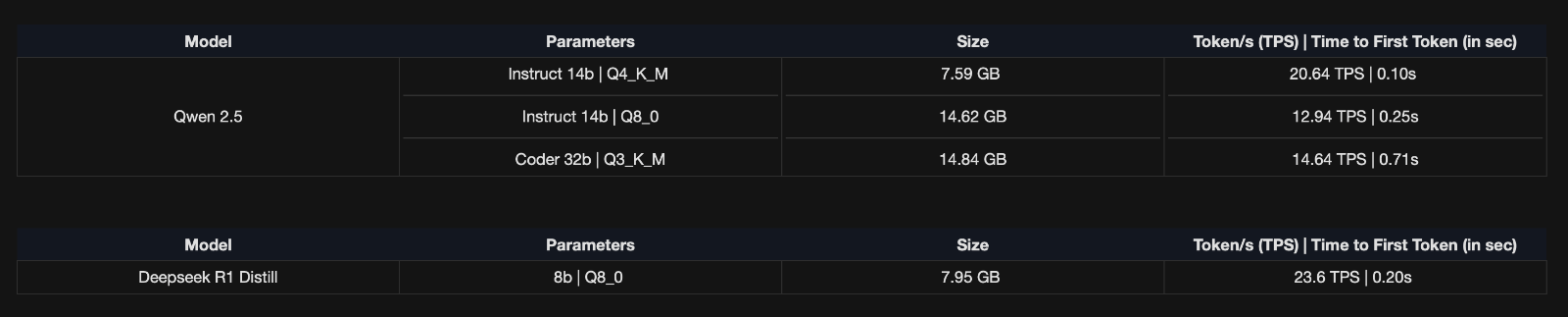
-
I also use Perplexity Pro. The “Auto Search” is usually ~40-50 TPS, but with much smaller models. If you want to use larger models, which is their “Deep Search” option, it reduces to ~5TPS.
-
When using locally, I use Llama 3.1 8b as a substitute for “Auto Search” in Perp. For “Deep Search”, I prefer Google Gemma 3 (27b) which gives as good as results, at twice the speed of Perplexity.
-
In my experience, anything above 10TPS is good. (I can read at a speed of ~4-5 TPS)
-
Recently, I also deployed Google’s Gemini 2.5 Pro. You can obtain API key via Google AI Studio. The limit is 50 free queries per day. It obliterates everything listed above (but can’t run locally).
Power Consumption
-
When idle (ubuntu server hosting personal website and database + Gemini 2.5 Pro API + network firewall + adguard home + wireguard server), the system consumes about ~42W of power.
-
When local LLM inferencing over WAN, it increases to ~168W (Gemma 3 27b with 4k tokens).
-
When cloud gaming, running MSFS 2024, and GPU under volt, total system power consumption is ~157W
All power is measured at the wall using [TP-Link Tapo P110](’
) smart monitor.
Outro
The machine is performing fine. It has been running 24x7 from the past one week or so. One of the most underrated feature of this setup is you can stream games at incredibly low bandwidth, thanks to AV1 encoders in Ada generation. Realistically, I have tested it at local cafe (connected to wifi @~15Mbps) playing MSFS 2024 at 1440p 60fps and it worked without stutters 95% of the time. The stutters could be very well due to GPU overheating, but I couldn’t verify at the time. This brings me to the main challenge I’ve been facing.


Cooling the 2000 ADA at stock using nerdware mod is difficult. The temperatures during stress tests jump to 88C. Upon under voting, the power consumption reduces to 54W at 810mV. It does bring temp down to 72C, but trades ~4% in performance in the process (total loss being 8% vs native when running in VM). I can’t imagine how some people are running the 4000 SFF inside this case.
Lastly, suggestions are welcome. Thanks for reading through it.