
Need help with pytorch....cannot resume training
- Thread starter draglord
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.

Ah I see the sample.py output the words are clearer/readable haha after running for 10,000 iterations.
Anyways, good luck with this, and do follow up post here if you find a solution to splitting your dataset (or maybe stream it or something) to fit in available memory...
...
Good morning @draglord
It appears that I can control the memory usage of train.py by setting the following 3 parameters which are present in the config py files...
batch_size, block_size and maybe also gradient_accumulation_steps.
Even the small shakespeare dataset memory usage drops from about 2 gb to 300 mb if I override the 2 settings.
I'm currently going to try the full openwebtext dataset with adjusted parameters...
Again I'm doing CPU mode only. I guess GPU video memory usage should also be affected by these settings?
What is the dataset you are training on? Size and memory consumption?
What is your config py file and have you tried lowering the 2 parameters to see if you can train it in your available memory without the need to split input files???
Anyways, good luck with this, and do follow up post here if you find a solution to splitting your dataset (or maybe stream it or something) to fit in available memory...
...
Good morning @draglord
It appears that I can control the memory usage of train.py by setting the following 3 parameters which are present in the config py files...
batch_size, block_size and maybe also gradient_accumulation_steps.
Even the small shakespeare dataset memory usage drops from about 2 gb to 300 mb if I override the 2 settings.
I'm currently going to try the full openwebtext dataset with adjusted parameters...
Again I'm doing CPU mode only. I guess GPU video memory usage should also be affected by these settings?
What is the dataset you are training on? Size and memory consumption?
What is your config py file and have you tried lowering the 2 parameters to see if you can train it in your available memory without the need to split input files???
Last edited:
Hi good morning
Yes the GPU settings should be affected by these as well.
I'm training on 5 gigs of data. Split into 3 files. Each of them takes about 6 gigs (out of 8gb)
Openwebtext is 40 gb. If you have more than 64 gb Ram i think you should be good to go.
I'll try lowering the 2 parameters to see if i can get the memory consumption to drop. But I'll need to train on bigger datasets (300gb +) so i think i would hit a limit there .
Yes the GPU settings should be affected by these as well.
I'm training on 5 gigs of data. Split into 3 files. Each of them takes about 6 gigs (out of 8gb)
Openwebtext is 40 gb. If you have more than 64 gb Ram i think you should be good to go.
I'll try lowering the 2 parameters to see if i can get the memory consumption to drop. But I'll need to train on bigger datasets (300gb +) so i think i would hit a limit there .
@Emrebel have you tried nanoGPT???
Whoa @draglord I just ran the openwebtext (so called clone of OpenAI's chatGPT) dataset (smallest init_from=gpt2 and also gpt2-xl) for few minutes training run (max_iters=100 only haha) and asked "What is OpenAI", "What is your name", and the sample "What is the answer to life, everything"...
It output rambling but kind of understandable for the latter 2 prompts, but "what is openAI" it actually spit out some relevant response!
Will try running for a bit longer and ask it some stuff LOL
Note, this is on CPU (I have threadripper 32 core and 128gb RAM) but just a RX580 8gb GPU, so will try running on GPU too and see if it speeds up even though memory is much less") Also, my 1gbit ftth connection helps with fast downloads of the bin files (6.5gb for gpt2-xl it downloads some pytorch bin related stuff).
Also, my 1gbit ftth connection helps with fast downloads of the bin files (6.5gb for gpt2-xl it downloads some pytorch bin related stuff).
Will try larger models (gpt2-xl and max_iters little higher values) and see what I get.
This is really intriguing stuff.
@draglord can I ask what is your dataset (300gb) and what is the config py file you are using?
Whoa @draglord I just ran the openwebtext (so called clone of OpenAI's chatGPT) dataset (smallest init_from=gpt2 and also gpt2-xl) for few minutes training run (max_iters=100 only haha) and asked "What is OpenAI", "What is your name", and the sample "What is the answer to life, everything"...
It output rambling but kind of understandable for the latter 2 prompts, but "what is openAI" it actually spit out some relevant response!
Will try running for a bit longer and ask it some stuff LOL
Note, this is on CPU (I have threadripper 32 core and 128gb RAM) but just a RX580 8gb GPU, so will try running on GPU too and see if it speeds up even though memory is much less
Also, my 1gbit ftth connection helps with fast downloads of the bin files (6.5gb for gpt2-xl it downloads some pytorch bin related stuff).Will try larger models (gpt2-xl and max_iters little higher values) and see what I get.
This is really intriguing stuff.
@draglord can I ask what is your dataset (300gb) and what is the config py file you are using?
Emrebel
Herald
I haven’t tried it yet. But will give it a shot.@Emrebel have you tried nanoGPT???
Whoa @draglord I just ran the openwebtext (so called clone of OpenAI's chatGPT) dataset (smallest init_from=gpt2 and also gpt2-xl) for few minutes training run (max_iters=100 only haha) and asked "What is OpenAI", "What is your name", and the sample "What is the answer to life, everything"...
It output rambling but kind of understandable for the latter 2 prompts, but "what is openAI" it actually spit out some relevant response!
Will try running for a bit longer and ask it some stuff LOL
Note, this is on CPU (I have threadripper 32 core and 128gb RAM) but just a RX580 8gb GPU, so will try running on GPU too and see if it speeds up even though memory is much less
Will try larger models (gpt2-xl and max_iters little higher values) and see what I get.
This is really intriguing stuff.
@draglord can I ask what is your dataset (300gb) and what is the config py file you are using?
Gradient accumulation is handy technique for mimicking large batch sizes.
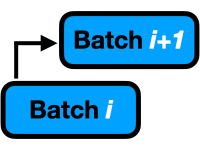

From the blogspot:
Gradient accumulation modifies the last step of the training process. Instead of updating the network weights on every batch, we can save gradient values, proceed to the next batch and add up the new gradients. The weight update is then done only after several batches have been processed by the model.
@Emrebel have you tried nanoGPT???
Whoa @draglord I just ran the openwebtext (so called clone of OpenAI's chatGPT) dataset (smallest init_from=gpt2 and also gpt2-xl) for few minutes training run (max_iters=100 only haha) and asked "What is OpenAI", "What is your name", and the sample "What is the answer to life, everything"...
It output rambling but kind of understandable for the latter 2 prompts, but "what is openAI" it actually spit out some relevant response!
Will try running for a bit longer and ask it some stuff LOL
Note, this is on CPU (I have threadripper 32 core and 128gb RAM) but just a RX580 8gb GPU, so will try running on GPU too and see if it speeds up even though memory is much less
Will try larger models (gpt2-xl and max_iters little higher values) and see what I get.
This is really intriguing stuff.
@draglord can I ask what is your dataset (300gb) and what is the config py file you are using?
Nice. I didn't try openwebtext yet as i don't have enough Ram.
Yeah stuff is really cool. I'm using the stack dataset

bigcode/the-stack · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
My processor and ram are the limitations. I think you have enough Ram to process some really large datasets in one go.
I didn't try openwebtext yet as i don't have enough Ram.
Have you tried those params (reducing batch_size, block_size and that 3rd gradient_accum one) yet? I think you might be able to run on your existing dual GPUs the openwebtext dataset and try running queries against it?
Tokenizing the data is a ram intensive process. Training is gpu intensive.Have you tried those params (reducing batch_size, block_size and that 3rd gradient_accum one) yet? I think you might be able to run on your existing dual GPUs the openwebtext dataset and try running queries against it?
When i create the train.bin and val.bin files data is read through ram. And i don't have enough of it
I figured out what the problem was.
Max_iters was set to 5000, and when training resumed, 5000 steps were already completed. So to remedy that i ran the (part of training) script in a loop, and then i passed new values to max_iters, and voila, i could resume training.
Thank you for your help @vishalrao
Last edited:
Oh brilliant, enjoy.
On my side looks like my RX580 is too outdated and I get segmentation faults while starting the iterations.
I'll just run CPU mode for a few hours on the openwebtext dataset and see what kind of responses I get to some prompts.
This has been a fun weekend thanks to you posting this thread haha TIL about nanoGPT.
On my side looks like my RX580 is too outdated and I get segmentation faults while starting the iterations.
I'll just run CPU mode for a few hours on the openwebtext dataset and see what kind of responses I get to some prompts.
This has been a fun weekend thanks to you posting this thread haha TIL about nanoGPT.
w00000t !!!
Was able to get my RX580 GPU to work with nanoGPT!
Spent many hours to figure it out but essentially the latest ROCm 5.5.1 version along with pytorch compiled from source after properly setting the GPU architecture target to gfx803 which is the old deprecated setting for the rx580, which works!
...
Lots of complaints and criticism about AMD not doing a good job of supporting older GPU models like mine apparently dropped a while back.
...
@draglord would you do a quick test for me on your GPU?
The default "dtype" parameter is set to BFLOAT16 which I believe is NOT natively supported in hardware on most GPUs except the very latest RTX 4000 series (and maybe AMD 7000 series) and when I override the param to FLOAT32 (by editing the train.py or passing param "--dtype=float32") I get about an apparent 30% increase in training speed using my old RX 580.
Could you let me know what/if you see any speed improvement on your side? Just need to run a short loop (few iterations logged) which you can cancel as soon as you see the following log output to compare:
For me the bold part dropped from about 64ms to 42ms when log_interval=10 - wondering what results you get.
Thanks!
Second question - are you able to run with --compile=True default option or do you have to set --compile=False? Currently my compile option fails with missing cuda.h header, so need to figure out how to get it to work.
Was able to get my RX580 GPU to work with nanoGPT!
Spent many hours to figure it out but essentially the latest ROCm 5.5.1 version along with pytorch compiled from source after properly setting the GPU architecture target to gfx803 which is the old deprecated setting for the rx580, which works!
...
Lots of complaints and criticism about AMD not doing a good job of supporting older GPU models like mine apparently dropped a while back.
...
@draglord would you do a quick test for me on your GPU?
The default "dtype" parameter is set to BFLOAT16 which I believe is NOT natively supported in hardware on most GPUs except the very latest RTX 4000 series (and maybe AMD 7000 series) and when I override the param to FLOAT32 (by editing the train.py or passing param "--dtype=float32") I get about an apparent 30% increase in training speed using my old RX 580.
Could you let me know what/if you see any speed improvement on your side? Just need to run a short loop (few iterations logged) which you can cancel as soon as you see the following log output to compare:
iter 50: loss 3.2720, time 42.04ms, mfu 0.06%
For me the bold part dropped from about 64ms to 42ms when log_interval=10 - wondering what results you get.
Thanks!
Second question - are you able to run with --compile=True default option or do you have to set --compile=False? Currently my compile option fails with missing cuda.h header, so need to figure out how to get it to work.
Last edited:
Update: The 30% improvement was with the shakespear-char (tiny) dataset but I see a massive 6X (600% or is it 500%) improvement with the mini GPT2 dataset when changing the dtype from bfloat16 to float32 running on my RX580 lol.
@vishalrao i changed the dtype from bfloat16 to float32 and the traning time dropped from 60 ms to 20 ms. But i think changing the dtype takes a hit on the quality of the model. But i should let you know i received an Out of memory error while changing the dtype, so i reduced the batch and block size as well
Oh interesting I didn't realise dtype could affect quality of the training, I thought it was a low level "under the hood" thingy and higher level pytorch, triton APIs just work the same.
I had posted a comment in the nanoGPT repo in one open PR which someone proposes to change the dtype for hardware that doesn't support bfloat16 but nobody mentioned this point so far, lets see.
I had posted a comment in the nanoGPT repo in one open PR which someone proposes to change the dtype for hardware that doesn't support bfloat16 but nobody mentioned this point so far, lets see.
Emrebel
Herald
Half precision float training is supposed to deliver performance close to full precision models while having lower training and inference times.@vishalrao i changed the dtype from bfloat16 to float32 and the traning time dropped from 60 ms to 20 ms. But i think changing the dtype takes a hit on the quality of the model. But i should let you know i received an Out of memory error while changing the dtype, so i reduced the batch and block size as well
I am not really sure how you get lower training time on float32. Ya but the model size will definitely increase if you use FP32.
FP16 (Half precision) is designed for lighter models that can be deployed to smartphones.
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
I am not really sure how you get lower training time on float32.
I think the lower training time on FP32 is relative to BF16 (and not FP16) where the latter (bfloat16) is not available in consumer gaming GPU hardware (even though they have tensor cores) but only in the datacenter GPUs maybe?
Emrebel
Herald
Yes could be a possible reason. I will check if the consumer grade gpus can support fp16.I think the lower training time on FP32 is relative to BF16 (and not FP16) where the latter (bfloat16) is not available in consumer gaming GPU hardware (even though they have tensor cores) but only in the datacenter GPUs maybe?
I have tested it once on a 3090 in my project and the model sizes were almost half compared to full precision models.
- Status
- Not open for further replies.